Kafka设计
##概要
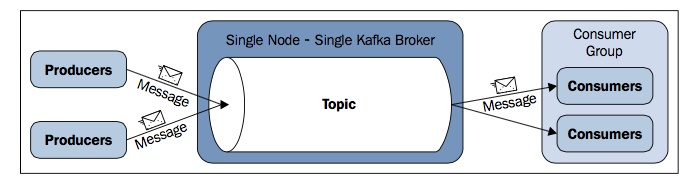
上图是一张单点单Broker的架构。
每一个consumer由进程表示。这些进程组成consumer group。一条消息由consumer group中的一个consumer消费。
如果一条消息需要多个consumer来处理,那么这些consumer需要在不同的consumer group中。
###重要的Kafka设计
1. Kafka的消息缓存和存储是基于文件系统的。在Kafka中数据被立即写到OS kernel page上。
缓存和刷新到磁盘是可配置的。
2. 在消息被消费后Kafka会保留一段时间,来满足消息的再消费需求。
3. Kafka把消息分组到消息集合中来减少网络消耗。
4. 与大多数消息系统不同的是Kafka需要consumer来维护已被消费的消息的状态。
这会导致 (失败时的消息丢失,同一条消息的多次投递)通常consumer会把这些信息存储在Zookeeper中。
5. producers和consumers采用传统的push-and-pull工作模型。
6. Kafka没有master的概念,所有的broker都是同级别的。所有的元数据都存储在Zookeeper中与producers和consumers共享。
7. Kafka(0.8.x)负载均衡使用Kafka的元数据API来完成,Zookeeper只用来确定有多少broker。
8. Kafka的producer能选择采用同步还是异步的方式来发送数据。
##数据压缩
Producer使用GZIP或Snappy来压缩消息集合。
使用最少两个bit的头来表示压缩属性。
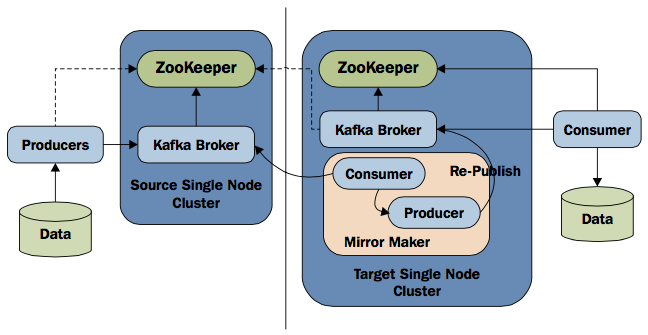
##集群镜像
这个特性是用来复制当前的Kafka集群。下图是mirroring tool的架构。
##Replication
###message partitioning
message partitioning策略是用由broker使用的。消息如何分片是由producer决定的。
broker存储顺序与它们到达的顺序一样。
每个Topic的分区数量是可配置的。
下图解释的Kafka的Replication原理
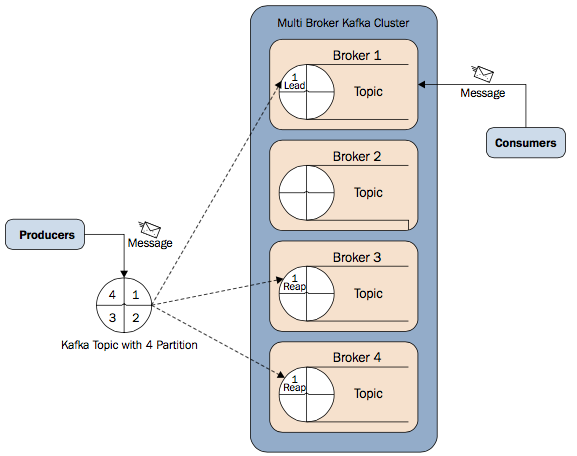
当lead replica故障时,正在写入local log和还没有发送ack的消息都会转到新的lead replica。
新lead replica由它们在Zookeeper上的注册时间决定。
###replication方式
1. 同步–producer从Zookeeper中确定lead replica并向它发送消息。当消息发布时,lead replica把它写入log,所有的所有的follower开始拉取消息。由于使用单一渠道,消息的顺序是被保证的。
当消息写入自己的Log后它会向lead replica 发送ack。当lead replica收到它所等待的所有ack后,它会向producer发送ack。
consumer只从lead replica上拉取消息。
2. 异步–与同步的不同是当消息写入local log后直接想producer发送ack。
blog comments powered by Disqus