Zookeeper内核
##请求 事物 标识
Zookeeper在本地处理读请求,所以读请求会非常快的返回。
Zookeeper的更新请求被转发到leader上。(我们把leader处理请求,更新状态称为一个事物)
在Zookeeper中事物是幂等的。
ZooKeeper transaction ID (zxid)来标识leader产生的新事物。zxid被leader用来建立Zookeeper秩序。
当选举新leader时,它们会交换zxid。
zxid是一个用64位标识的整数。可分为epoch和counter两部分,每个部分有32位。
##Leader选举
要成为leader必须要有quorum个server支持。
当需要选举或发现新的leader时server进入LOOKING状态。
如果leader已经存在它将从其它server获取leader的信息,并连接到leader上来保证它上面的信息与leader是一致的。
如果所有的server都在LOOKING状态,他们就需要选举出一个新的leader。赢得这场选举的server进入LEADING状态,其它的进入FOLLOWING状态。
###选举过程
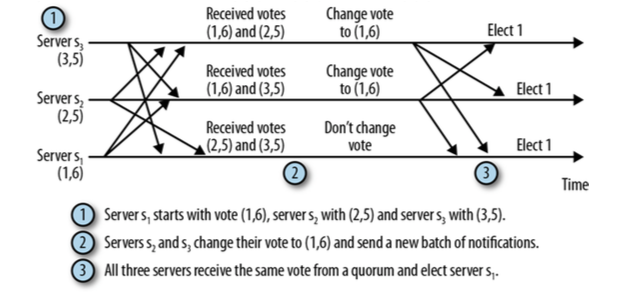
当server进入LOOKING状态时它会向所有其他server发送一条包含server id和zxid的通知。
我们记为(voteId,voteZxid)
收到通知的server根据如下规则:
假设mySid,myZxid分别为收到这个通知的server的sever id和zxid。
1. 如果(voteZxid > myZxid) 或者(voteZxid = myZxid && voteId > mySid)保持现有投票。
2. 否则使用自己的server id和zxid进行投票。
所以最新的zxid获胜,如果zxid相同则sid最大的获胜。
如果一台server收到的quorum个相同的vote那么他就标记选举结束,如果vote标记的是自己那么他就进入leader职责,不是的话就进入follower状态并连接到leader。
下图简单的描述了一次leader选举
##Observers
Observer不参与到投票中。
Observers接受包含已提交proposal的INFORM信息。
提供Observers这种模式主要是为了:
1. 读操作的可阔缩性。
2. 在不同数据中心的部署。
##Zookeeper骨架
###Leader Server
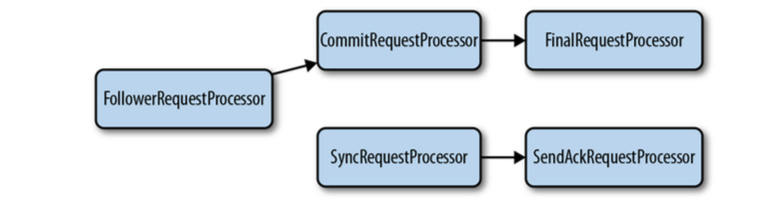
下图是leader的管道示意图:

下图是follower的管道示意图:
##本地存储
###日志和磁盘的使用
在接受proposal前server会把这个事物持久化到transaction log(一个在server本地磁盘上的事物顺序添加的文件)中。
Zookeeper会使用group commits和padding来提高transaction log的操作速度。
现代OS会缓存脏页面并异步的写入的磁盘上。Zookeeper在继续前需要保证事物已经被持久化,所以我们需要显示的调用flush操作。
由于我们在SyncRequestProcessor中持久化事物,所以我们把这个工作交给他。我们会对它做group commits优化。
需要关闭OS的disk write cache
###Padding
预分配disk blocks给文件。
###Snapshots
每个server会经常的序列化整个data tree并把他写入文件。
##Servers和Sessions
Session是Zookeeper中一个非常重要的概念。ephemeral znode和watches都和它有关。
Leader server,standalone server采用同样的Session跟踪器(SessionTracker and SessionTrackerImpl)
Follower只是转发leader跟踪的Session给client(LearnerSessionTracker)。
blog comments powered by Disqus