源码阅读 (4)DAGScheduler 粗解
DAGScheduler的主要任务是基于Stage构建DAG,决定每个任务的最佳位置。
记录哪个RDD或者Stage输出被物化
面向Stage的调度层,为job生成以stage组成的DAG,提交TaskSet给TaskScheduler执行
重新提交shuffle输出丢失的stage
每个Stage内都是独立的tasks。它们共同执行同一个compute function,有相同的shuffle dependencies。 DAG在切分stage的时候是依照出现的shuffle为界限的。
DAGScheduler是在SparkContext中实例化的。 它的构造函数中的主要参数为 SparkContext 和 TaskScheduler。
def this(sc: SparkContext) = this(sc, sc.taskScheduler)
###作业提交与DAGScheduler操作
action操作会进行job的提交。它的大致调用链为:
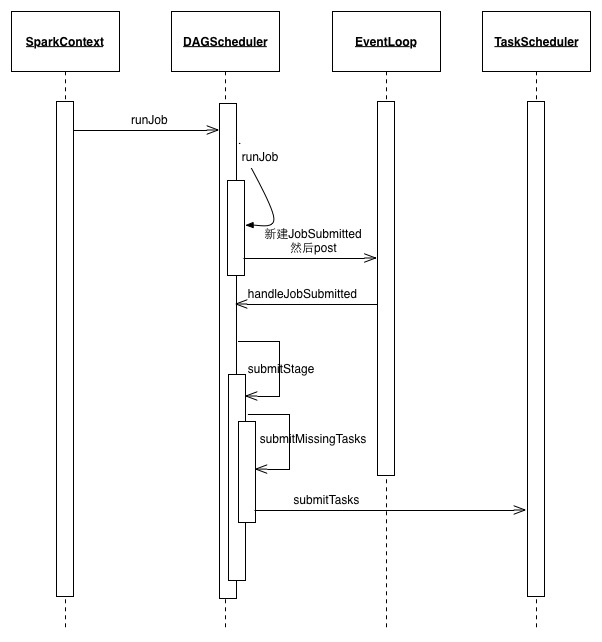
handleJobSubmitted会生成finalStage完成job到stage的转换,并调用submitStage来提交运行stage。 在submitStage中会计算stage之间的依赖关系。 如果计算中发现当前的stage没有任何依赖或者所有的依赖都已准备完毕,则调用submitMissingTasks来提交task。 task真正运行在哪个worker上面是由TaskScheduler来管理,也就是上面的submitMissingTasks会调用TaskScheduler的submitTaskS。 TaskSchedulerImpl会根据Spark当前的运行模式来运行Task。
###事件处理
DAGScheduler的submitJob会创建JobSubmitted的event发送给
private[scheduler] val eventProcessLoop = new DAGSchedulerEventProcessLoop(this)
他会调用 ~~~ scala private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) => dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
来处理event
###JobWaiter
JobWaiter继承自JobListener,实现了taskSucceeded和jobFailed函数。
~~~ scala
override def taskSucceeded(index: Int, result: Any): Unit = synchronized {
if (_jobFinished) {
throw new UnsupportedOperationException("taskSucceeded() called on a finished JobWaiter")
}
resultHandler(index, result.asInstanceOf[T])
finishedTasks += 1
if (finishedTasks == totalTasks) {
_jobFinished = true
jobResult = JobSucceeded
this.notifyAll()
}
}
override def jobFailed(exception: Exception): Unit = synchronized {
_jobFinished = true
jobResult = JobFailed(exception)
this.notifyAll()
}
blog comments powered by Disqus